백준 1181번 문제를 hash table과 구조체를 이용하여 풀어보았습니다.
백준 1181번: https://www.acmicpc.net/problem/1181
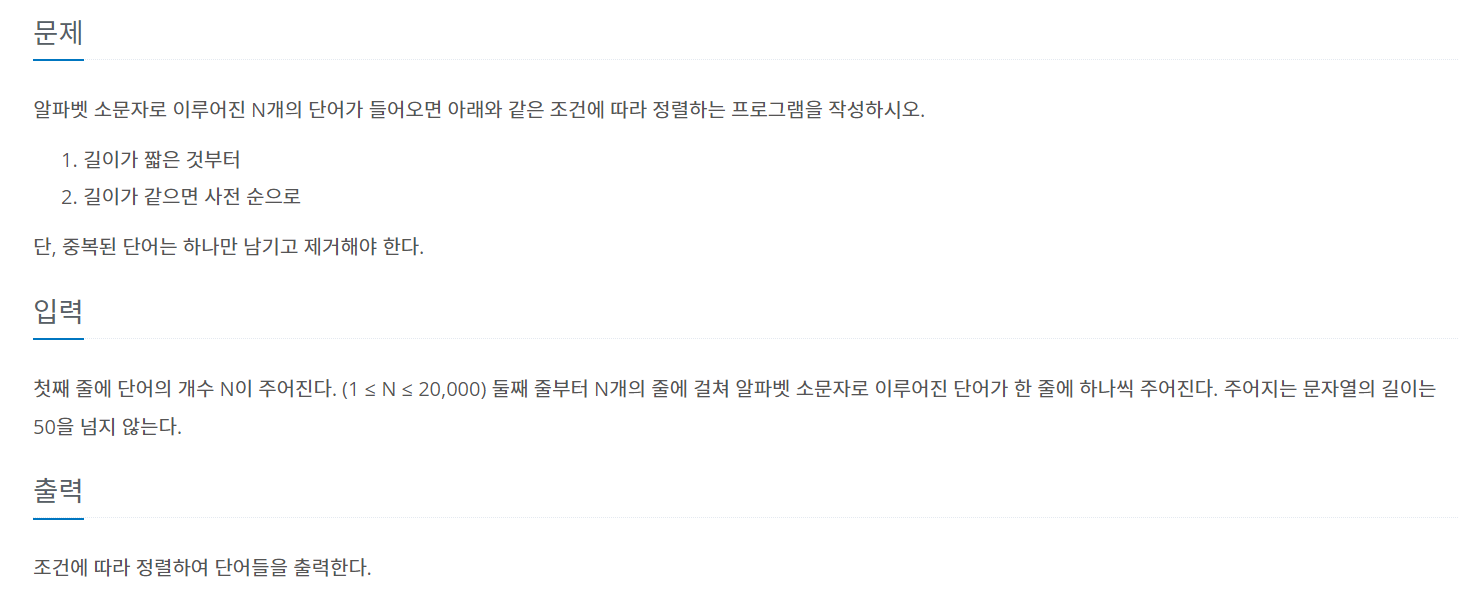
1181번: 단어 정렬
첫째 줄에 단어의 개수 N이 주어진다. (1 ≤ N ≤ 20,000) 둘째 줄부터 N개의 줄에 걸쳐 알파벳 소문자로 이루어진 단어가 한 줄에 하나씩 주어진다. 주어지는 문자열의 길이는 50을 넘지 않는다.
www.acmicpc.net
문제 내용은 아래와 같습니다.
이 문제 역시 정렬하는 것이지만 문자열을 정렬해야 하므로 신경 써야 할 것이 더 많습니다. 우리가 정수를 정렬할 때는 수의 크기 하나만 신경 쓰지만 여기서는 두 가지 요소 모두를 신경 써줘야 하기 때문에 더 복잡할 수 있습니다. 그래서 구현할 때 두 가지 요소 모두를 적용하기 위해 구조체와 hash table을 적절히 활용했습니다.
대략적인 방법을 말하자면, key값이 단어의 길이이고 value가 문자열인 hash table을 만들어서 입력받은 문자열을 저장해주고 그 순서대로 출력하는 방법입니다. 다만 hash table에서 중복된 key를 가질 경우 해결 방법이 여러 가지인데, 여기서는 정렬을 더 쉽게 하기 위해서 구조체를 활용한 linked list를 이용했습니다. c언어에서는 아무래도 이미 배열에 저장해 뒀으면 새로운 데이터가 기존에 저장된 데이터에 앞에 가야 하는 경우, 그 뒤 데이터를 다 밀어야 해서 과정이 복잡합니다. 그래서 linked list를 사용하여, 데이터를 끼워 넣는 과정을 간소화했습니다. 결국 애초에 단어들을 입력받을 때 hash table에 정렬을 모두 꺼내놓고, 순회하면서 출력만 할 수 있도록 구현했습니다.
코드를 보면 각 단어와 다음 노드를 저장할 WORDINFO 구조체를 wordInfo로 정의했고, helper function으로는 하나의 노드를 만드는 과정을 담은 makeElem() 함수를 사용했습니다. (지금 보니 함수를 사용해서 코드를 좀 정리할 걸 하는 생각도 드네요...)
메인 함수를 살펴보면 총 세가지 파트로 나뉘어 있습니다. 첫 번째 파트는 각 단어를 입력받으면서 정렬하는 파트이고, 두 번째는 정렬된 단어들을 출력하는 파트, 그리고 마지막으로 메모리를 해제하는 파트입니다.
// 파트1: 단어 입력받아 정렬하여 저장
wordInfo *words[51];
for (int i = 0; i < 51; i++) words[i] = NULL;
char inWord[51];
int len;
for (int i = 0; i < N; i++) {
scanf("%s", inWord);
len = strlen(inWord);
if (words[len] == NULL) // 경우1: 같은 길이의 단어가 없는 경우
words[len] = makeElem(inWord, NULL);
else { // 경우2: 같은 길이의 단어가 있는 경우
wordInfo *curr = words[len];
int cmp = strcmp(curr->word, inWord);
if (cmp == 0) {
continue;
} else if (cmp > 0) {
words[len] = makeElem(inWord, words[len]);
} else {
while (curr->next) {
cmp = strcmp(curr->next->word, inWord);
if (cmp >= 0)
break;
curr = curr->next;
}
if (cmp != 0)
curr->next = makeElem(inWord, curr->next);
}
}
}
위에 코드로 나와있는 첫번째 파트를 자세히 보겠습니다. 단어를 입력받기 위해서 우선 wordInfo 구조체를 담을 배열을 선언해 주고, 모든 값을 NULL로 초기화해 줍니다. 다음 각각의 단어를 임시로 입력받을 inWord 문자열도 선언해 줍니다. 그 이후 반복문을 통해 단어를 받고 문자열 길이를 재서 상황에 따라 올바른 위치에 넣어줍니다.
올바른 위치에 넣기 위한 경우는 크게 두가지가 있는데, 이미 앞서 입력받은 같은 길이의 단어가 있는 경우와 없는 경우입니다. 같은 길이의 단어를 입력받지 않은 경우, 배열의 해당 위치는 NULL값일 것이고, 그렇다면 노드 하나를 생성하여 바로 넣어주면 됩니다.
하지만 이미 입력받은 같은 길이의 단어가 있는 경우, 정렬된 올바른 위치를 찾아서 넣어주어야 하므로 조금 더 복잡한 과정을 거쳐야 합니다. 우선 첫 번째 단어를 cur 변수에 넣고, 현재 입력받은 단어와 첫 번째 단어를 비교하여 다시 3가지 경우로 나눕니다. 첫 번째 단어가 현재 입력받은 단어와 같은 경우는 문제에 따라 같은 단어는 하나만 남겨야 하므로 저장하지 않고 바로 continue 해줍니다. 만약 첫 번째 단어가 현재 입력받은 단어보다 뒷순서인 경우에는 첫 번째 단어 자리를 현재 입력받은 단어에게 주고, 기존 첫 번째 단어를 현재 입력받은 단어의 next 노드 자리에 넣어줍니다. 세 번째로 그 외의 경우에는 다시 현재 입력받은 단어의 적절한 자리를 여러 개의 같은 길이의 단어들 사이에서 찾아야 합니다. while문으로 linked list를 순회하면서 계속 현재 단어와 저장된 단어들을 비교하여, 탐색 중인 단어의 다음 단어가 현재 단어보다 뒷순서 거나 같은 경우 순회를 종료하여 위치를 찾습니다. 이때 단어들이 같을 경우 저장하지 않지만, 그렇지 않을 경우에는 탐색을 종료한 시점의 단어 다음 자리를 현재 단어에게 주고, 원래 다음 단어를 현재 단어의 다음에게 줍니다. 말이 복잡해서 아래와 같이 손글씨와 예시로 표현해 봤으니 참고해주시 바랍니다.

// 파트2: 정렬된 단어 순서대로 출력
for (int i = 0; i < 51; i++) {
if (words[i]) {
wordInfo *curr = words[i];
while (curr) {
printf("%s\n", curr->word);
curr = curr->next;
}
}
}
두번째 파트에서는 첫 번째 파트에서 순서대로 정렬해 둔 것을 출력하기만 하면 됩니다. hash table을 처음부터 끝까지 순회하면서 만약 해당 위치에, 즉 해당 인덱스의 길이를 가진 단어가 존재한다면 linked list를 순회하면서 출력해 주면 됩니다.
// 파트3: 메모리 해제
for (int i = 0; i < 51; i++) {
if (words[i]) {
wordInfo *pre = words[i];
wordInfo *cur = pre->next;
while (cur) {
free(pre);
pre = cur;
cur = cur->next;
}
free(pre);
}
}
세번째 파트에서는 만들어 둔 hash table 내 각 노드에 할당했던 메모리를 해제해주어야 하는데요, cur 변수에서 바로 free를 적용해 주면 다음 노드에 접근할 수 없게 되기 때문에 pre와 cur 변수를 하나씩 선언하여 pre 변수를 free 해주는 식으로 접근해야 합니다.
아래는 전체 코드입니다. 함수를 나눠서 좀 더 깔끔하게 정리했으면 좋았을 것 같은데 그러지 못해서 파트 별로 나눠서 설명을 작성했습니다. 이해하기 쉬운 설명이었기를 바랍니다.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct WORDINFO {
char word[51];
struct WORDINFO *next;
} wordInfo;
wordInfo *makeElem(char inWord[51], wordInfo *n) {
wordInfo *w = (wordInfo *)malloc(sizeof(wordInfo));
if (w == NULL)
return NULL;
strcpy(w->word, inWord);
w->next = n;
return w;
}
int main() {
int N;
scanf("%d", &N);
// 파트1: 단어 입력받아 정렬하여 저장
wordInfo *words[51];
for (int i = 0; i < 51; i++) words[i] = NULL;
char inWord[51];
int len;
for (int i = 0; i < N; i++) {
scanf("%s", inWord);
len = strlen(inWord);
if (words[len] == NULL) // 경우1: 같은 길이의 단어가 없는 경우
words[len] = makeElem(inWord, NULL);
else { // 경우2: 같은 길이의 단어가 있는 경우
wordInfo *curr = words[len];
int cmp = strcmp(curr->word, inWord);
if (cmp == 0) {
continue;
} else if (cmp > 0) {
words[len] = makeElem(inWord, words[len]);
} else {
while (curr->next) {
cmp = strcmp(curr->next->word, inWord);
if (cmp >= 0)
break;
curr = curr->next;
}
if (cmp != 0)
curr->next = makeElem(inWord, curr->next);
}
}
}
// 파트2: 정렬된 단어 순서대로 출력
for (int i = 0; i < 51; i++) {
if (words[i]) {
wordInfo *curr = words[i];
while (curr) {
printf("%s\n", curr->word);
curr = curr->next;
}
}
}
// 파트3: 메모리 해제
for (int i = 0; i < 51; i++) {
if (words[i]) {
wordInfo *pre = words[i];
wordInfo *cur = pre->next;
while (cur) {
free(pre);
pre = cur;
cur = cur->next;
}
free(pre);
}
}
}
'기초 공부 (언어 및 알고리즘) > 알고리즘 (C언어)' 카테고리의 다른 글
| [백준 10828번/C언어] 스택 풀이 (1) | 2024.03.21 |
|---|---|
| [백준 1260번/C언어] 미로 탐색, BFS로 풀이 (3) | 2024.03.20 |
| [백준 10989번/C언어] 수 정렬하기 3, 배열을 활용한 풀이 (0) | 2024.03.17 |
| [백준 1260번/C언어] DFS와 BFS, Queue로 풀이 (0) | 2024.03.17 |
| [백준 1654번/C언어] 랜선 자르기, 이진탐색으로 풀이 (0) | 2024.03.15 |